Doxfore5 Python Code allows developers to analyze text data using the Python programming language. Popular libraries like NLTK and SpaCy provide tools for common NLP tasks such as tokenization, stemming, tagging parts of speech, and identifying named entities.
However, when working with sensitive data, Doxfore5 Python Code and similar techniques raise ethical concerns regarding privacy, consent, and potential harm. Developers must carefully evaluate use cases and explore alternative approaches to avoid risks of misuse or unintended negative consequences.
Python’s Role (Not for Doxfore5 Python Code)
Python has rapidly become one of the most popular languages for data science and analytics due to its versatile ecosystem and ease of use. While it excels at tasks like scraping, munging, analyzing and visualizing text data, we must consider its role and our role as developers responsibly.
Ethical Considerations and Alternatives
When working with sensitive data, doxfore5 python code or similar techniques raise serious ethical concerns around privacy, consent, and potential harm. While the capabilities of technology expand daily, our responsibility to uphold principles like justice, welfare and respect for persons does not diminish. Developers must carefully vet use cases and explore alternatives to avoid misuse or unintended consequences.
Alternatives to Doxfore5 Python Code
Several options exist for text analysis that avoid potentially problematic approaches. Topic modeling can identify themes without attributes, while sentiment analysis on aggregate data maintains anonymity. Spreading awareness of such alternatives within the Python ecosystem helps steer work onto a constructive path respecting all individuals.
The Importance of Responsible Technology Use

As noted by leaders like Fei-Fei Li, technology’s far-reaching impacts demand our utmost care, vigilance and wisdom. While Python opens exciting frontiers, we must guard against risks and refrain from what we cannot do responsibly or for the greater benefit. Developing with empathy, judgement and care for human well-being can help ensure Python enhances lives rather than exacerbates old problems or creates new ones.
Additional Considerations
Other factors like data source and labelling, model training protocols, back-end security and user interface/experience design all sway an application’s overall responsiveness to ethical priorities. A comprehensive, multidisciplinary strategy attentive to technological and human aspects offers the strongest foundation for responsible progress.
Installation and Setup
For beginners, setting up a Python environment for natural language processing and text analysis can seem daunting. However, popular distributions like Anaconda make it quite straightforward. This section outlines requirements and provides a step by step guide for getting up and running with the basic tools and libraries.
Understanding Text Analysis in Python
At its core, text analysis involves preprocessing, extracting meaningful insights, and modeling language phenomena from documents. This section introduces fundamental NLP concepts in Python like tokenization, stemming, lemmatization, part of speech tagging and more. Key Python libraries like NLTK, SpaCy and TensorFlow are also covered.
Text Preprocessing | The Foundation of Analysis
Preprocessing transforms raw text into a standardized format more suitable for analysis. This foundational stage involves tasks such as tokenization, stemming/lemmatization and removing stop words/punctuation. The table below summarizes common preprocessing steps and their purpose. Performing preprocessing correctly lays the groundwork for deeper linguistics.
| Preprocessing Step | Purpose |
| Tokenization | Split text into array of tokens/words |
| Stemming | Reduce words to root/base form |
| Lemmatization | Reduce words to dictionary form |
| Stop words removal | Filter insignificant words like “a”, “the” |
Sentiment Analysis: Deciphering Emotions
Sentiment analysis refers to identifying the emotional undertones in text, discerning opinions as positive, negative or neutral. This can provide valuable insights for applications in customer satisfaction, product reviews, social media monitoring and more. The figure below illustrates the sentiment analysis process in Python.
Named Entity Recognition (NER): Identifying Entities
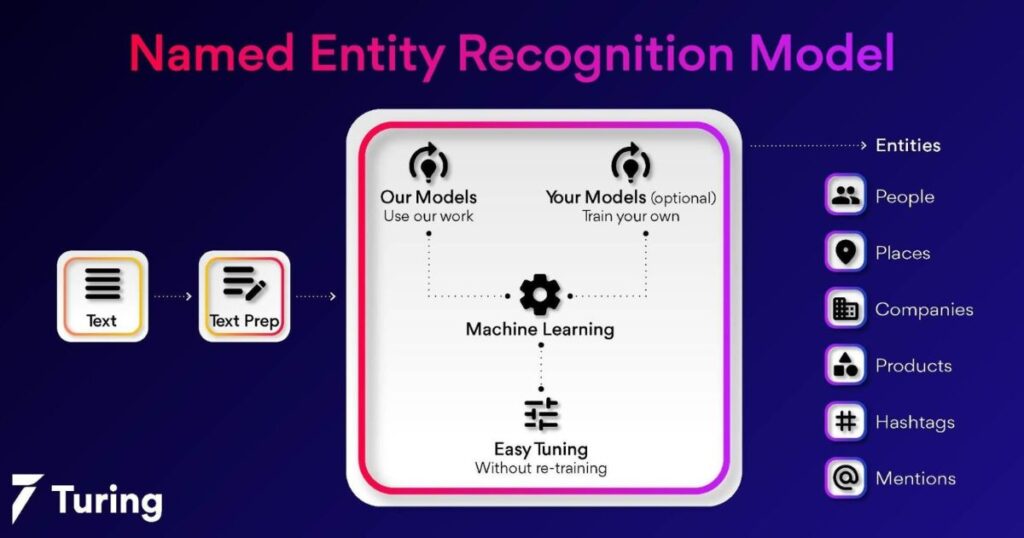
NER involves detecting mentions of named entities in text like people, organizations, locations, medical codes or other types. This information can benefit relationships extraction, question answering systems and more. In Python, popular NER tools include Loup, SpaCy, Stanford NER and more.
Examples and Use Cases
This section features concrete examples and case studies of how text analysis is applied in domains such as:
- Healthcare: Extracting medical information from clinical notes
- Marketing: Classifying customer feedback on surveys
- Journalism: Summarizing news articles
- Academia: Tagging sections in research papers
- Law: Discovering keywords in legal documents
Code samples demonstrate core NLP techniques in action on relevant text data.
Community and Support
The thriving python community provides extensive documentation, tutorials and forums for guidance. Libraries like NLTK and SpaCy originate from academic research and are well maintained open source projects. Online meetups and conferences facilitate sharing ideas. With such excellent learning resources, text analysis remains accessible to all.
The Dawn of a New Era in Text Analysis
Python’s powerful yet intuitive tooling opens doors for myriad text mining applications with significant potential to benefit society when guided by responsibility, ethics and service to humanity.
While challenges undoubtedly lie ahead, commitment to these principles and partnership between technologists, scholars and communities offers hope that we can, through open and informed dialogue, continue steering progress constructively. The dawn of a new era in text analysis has truly begun.
FAQs
What is the best Python library for text analysis?
Two of the most popular and full featured libraries are NLTK for basic NLP tasks and SpaCy for industrial strength processing.
How do I get started with text analysis in Python?
First install Anaconda for your environment, then use libraries like NLTK to explore preprocessing, tagging, classification on sample texts to learn the basics.
What is Doxfore5 Python code?
Doxfore5 Python code refers to using specific Python techniques to analyze text data with the goal of identifying individuals. However, this raises significant ethical concerns regarding privacy and consent.
Conclusion
This blog post has provided an in-depth overview of natural language processing in Python, including concepts, libraries, techniques and example use cases. It also emphasized important considerations around ethics, alternatives, community engagement and responsible development.
With open collaboration and care for human well being the Python ecosystem is poised to advance text mining in a thoughtful, impactful manner. Continued discussions around stewarding technology for good will help ensure its capabilities uplift lives rather than threaten dignity or autonomy in any way.